¶ Dataset Structure
EMBED consists of images and two primary tables:
- Clinical Data Table (AKA Magview): Contains the clinical information for each patient, exam, and finding in EMBED. Most columns were collected from the breast radiology EHR system at Emory, with some other features merged in from other data sources.
- Image Metadata Table: This table contains metadata for each image in EMBED. Most columns in metadata were collected by determining a set of attributes that were consistent in most of our DICOMs, then scraping this data from each and storing them in a table. Other columns were derived using models or algorithms to simplify operations.
¶ Clinical/Metadata Hierarchies
When working with EMBED it's very important to understand how its data hierarchies interact with one another. An overview of the hierarchy is shown in Figure 1.
- Cohorts: Patients in EMBED are randomly sampled into 10 approximately equal cohorts (
cohortnum) that do not overlap with one another (the public Open Data version only contains the first 2 cohorts). - Patients: Each patient ID (
empi_anon) refers to all data from 1 unique patient. All exams, images, and findings for a patient will be linked with this column. - Exams: Each exam ID (
acc_anon), also called an accession, refers to all data from 1 unique exam for a patient. All images and findings for a given exam will be linked with this column. - Sides: Results from each side of an exam (for bilateral exams, unilateral exams will only contain results from one side) can be indexed using the
sidecolumn in the clinical data, and theImageLateralityFinalcolumn in the metadata. - Images: Each row of the metadata table refers to one unique image.
- Findings: Each row of the clinical table refers to one unique finding (see caveat to this below). Findings can also be identified with the
numfindcolumn which enumerates each unique finding within an exam. - Procedures: Procedures are generally linked to at least one finding and indicate the presence of a biopsy or surgical procedure (and any related pathology results). If a finding has more than one linked procedure, for example a biopsy followed by a lumpectomy with unique pathology reports for each, a finding row may be duplicated with only the procedure details differing between the two (
numfindshould be used to identify unique findings in these cases).
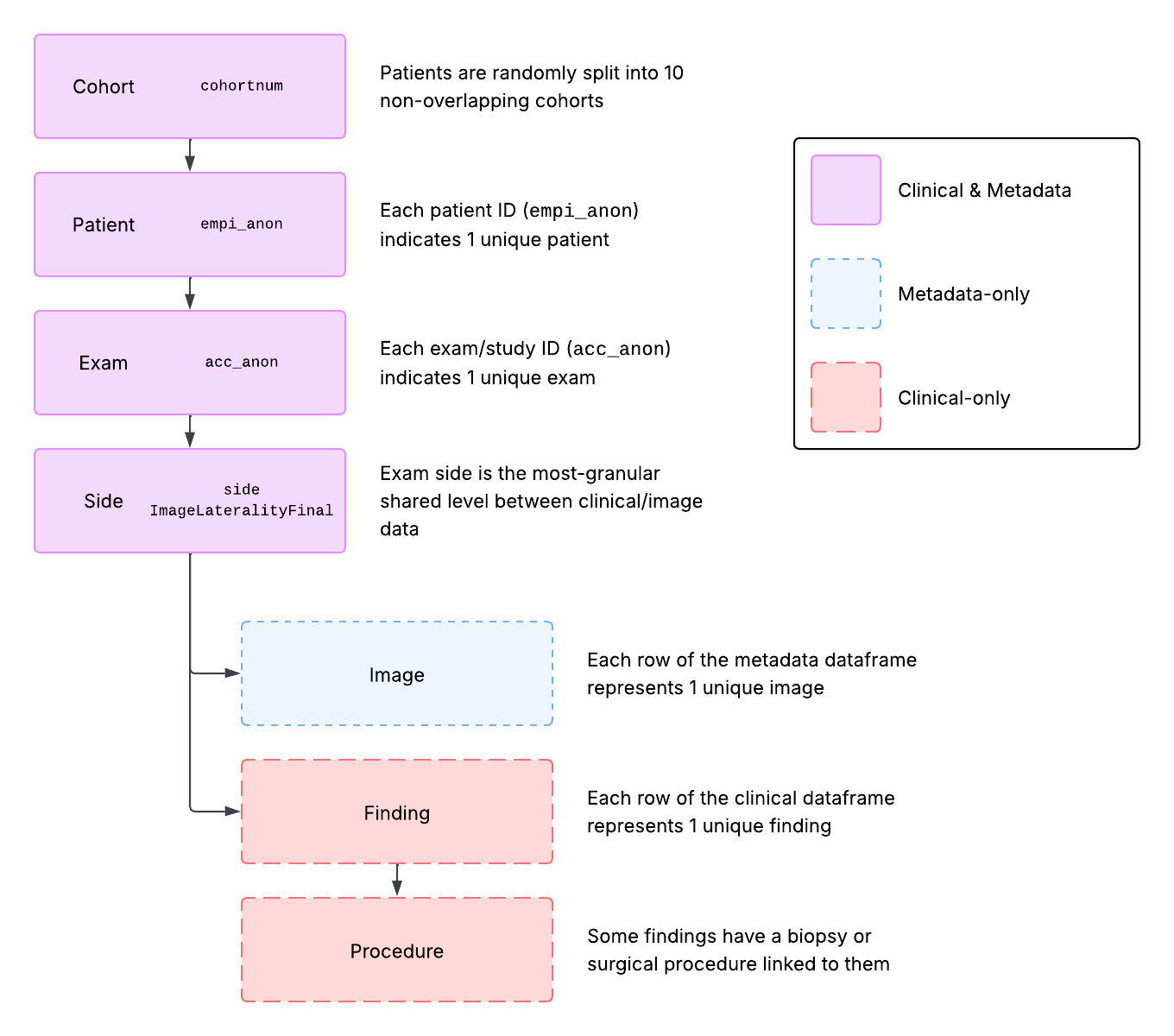
Figure 1: Data hierarchy diagram for EMBED
¶ Working with the Clinical/Metadata
Figure 2 shows how these hierarchies are represented in the EMBED tables (cohort not shown). Patient, exam, and side identifiers are present in both tables, while images are unique to the metadata and findings/procedures are unique to the clinical data.
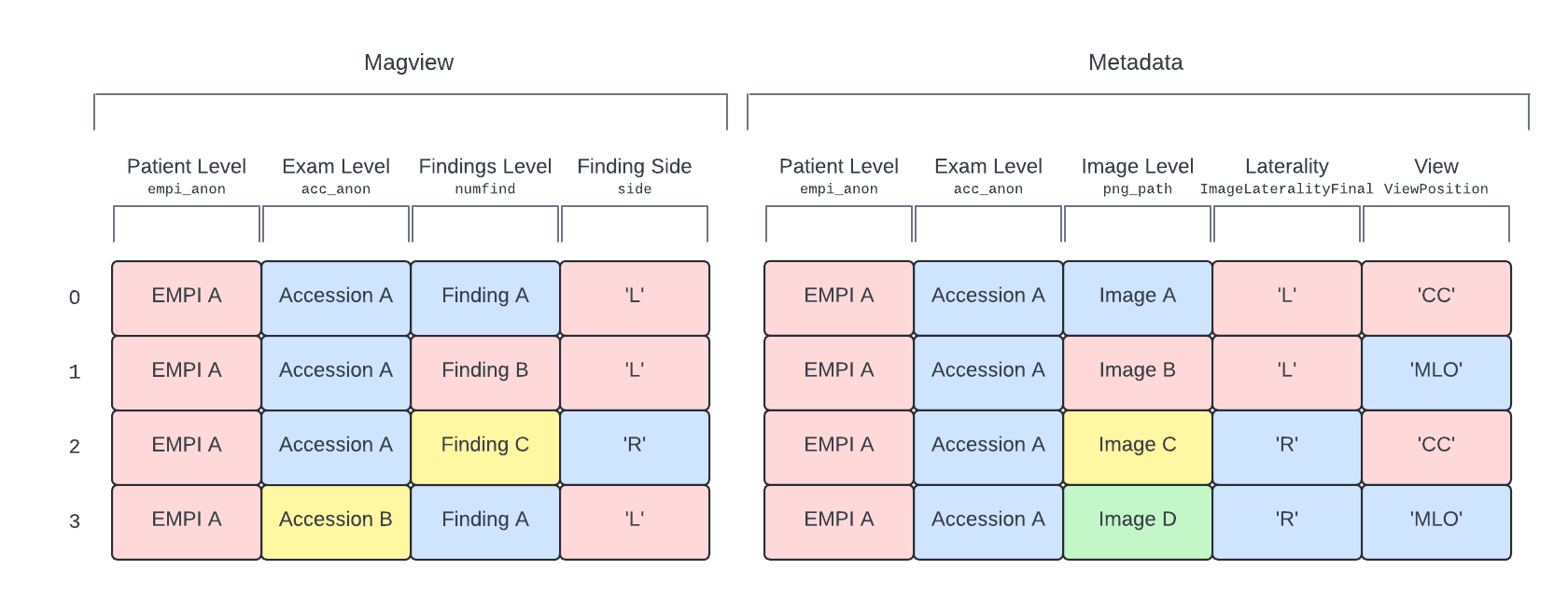
Figure 2: Visual representation of the EMBED data hierarchy in the clinical (shown here as: Magview) and metadata tables
Figure 3 shows the data engineering order of operations we generally recommend when working with EMBED. The two tables can technically be merged whenever (even at the very start) but keeping the two separate for as long as possible generally helps to keep operations clearer and prevents unintended duplications.
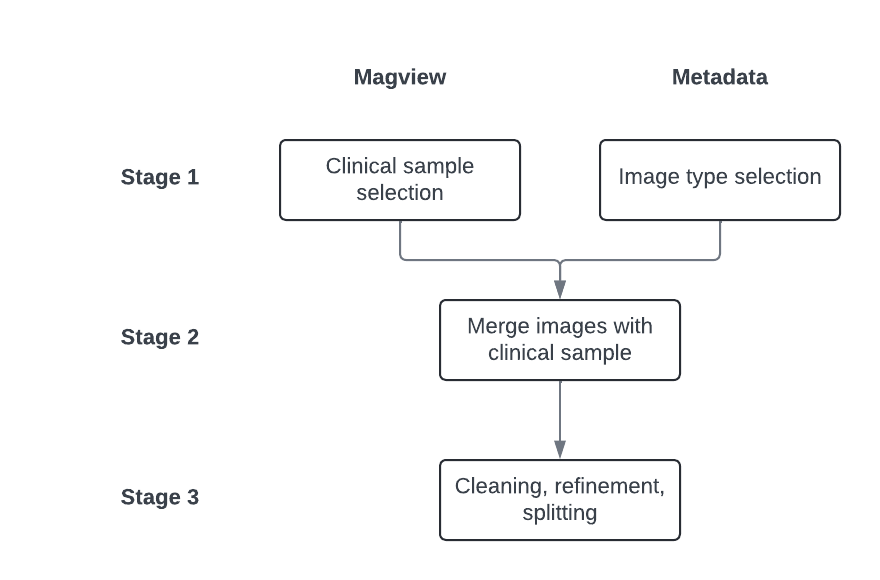
Figure 3: Flowchart of the recommended data engineering approach for the clinical (shown here as: Magview) and metadata tables
For example, when trying to define a cancer versus no-cancer dataset with only 3D images, we would do the following:
- In the clinical data, assign labels indicating exams with and without cancer pathology results. Exclude any exams that are considered invalid for the study based on the available clinical information. Assign side-level labels and deduplicate so there is exactly one row for each exam side.
- In the metadata, select only the images where
FinalImageType == '3D' - Merge the selected clinical data and metadata on the
acc_anonand side columns (sidein clinical,ImageLateralityFinalin metadata). Ensure data is deduplicated and handle any final splitting or cleaning. - Finally, use the
anon_dicom_pathcolumn to match the relevant images to your dataset.